python:Requests+正则爬取网页数据
本文共 328 字,大约阅读时间需要 1 分钟。
前言本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取
1.分析网页确定思路
打算爬取猫眼电影的 top 100 的电影信息,我们首先可以访问一下我们需要爬取的网站,看一下我们需要的信息所处的位置和结构如何
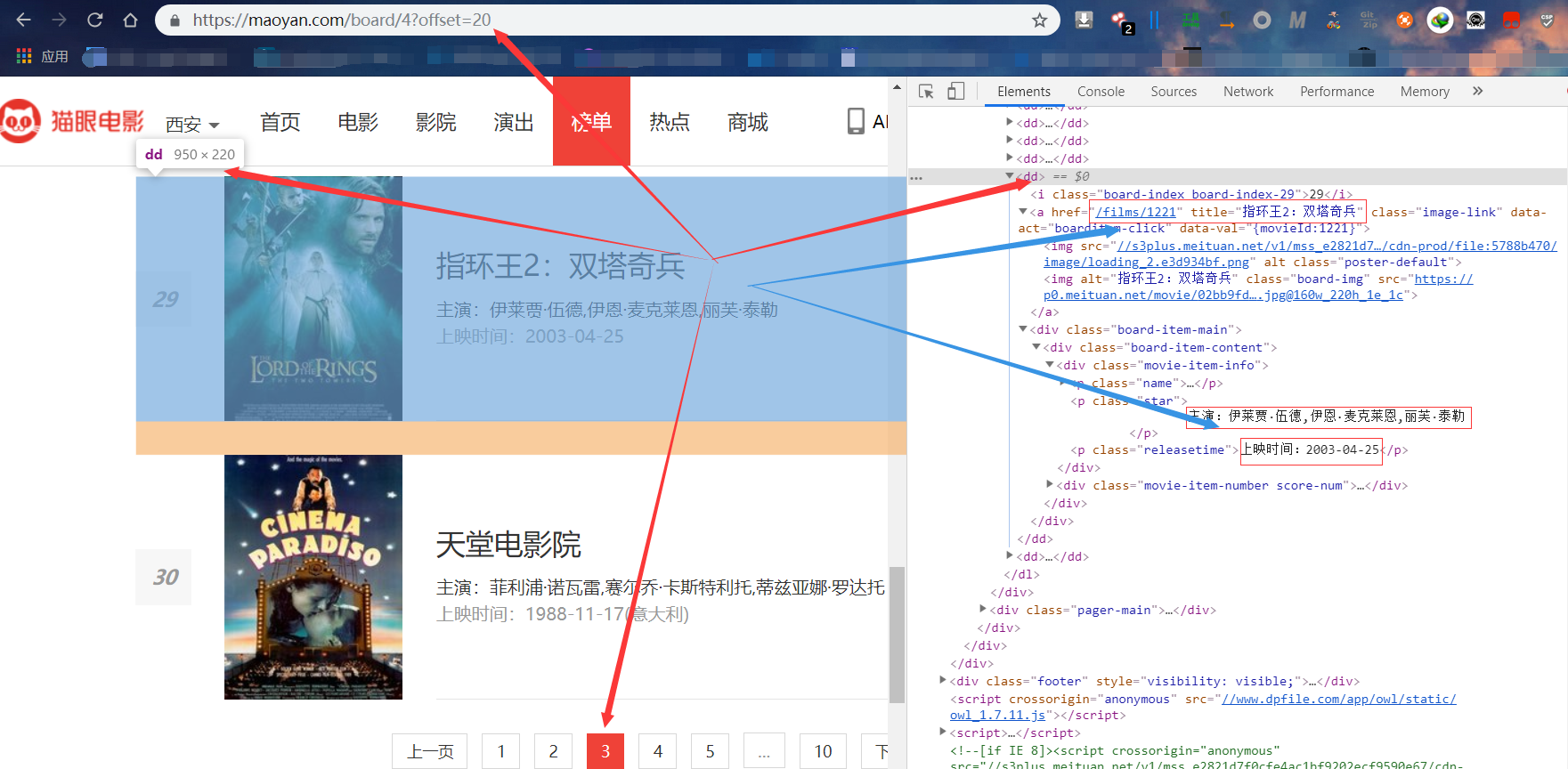
看完以后我们的思路应该就比较清晰了,我们首先使用 requests 库请求单页内容,然后我们使用正则对我们需要的信息进行匹配,然后将我们需要的每一条信息保存成一个JSON 字符串,并将其存入文件当中,然后就是开启循环遍历十页的内容或者采用 Python 多线程的方式提高爬取速度
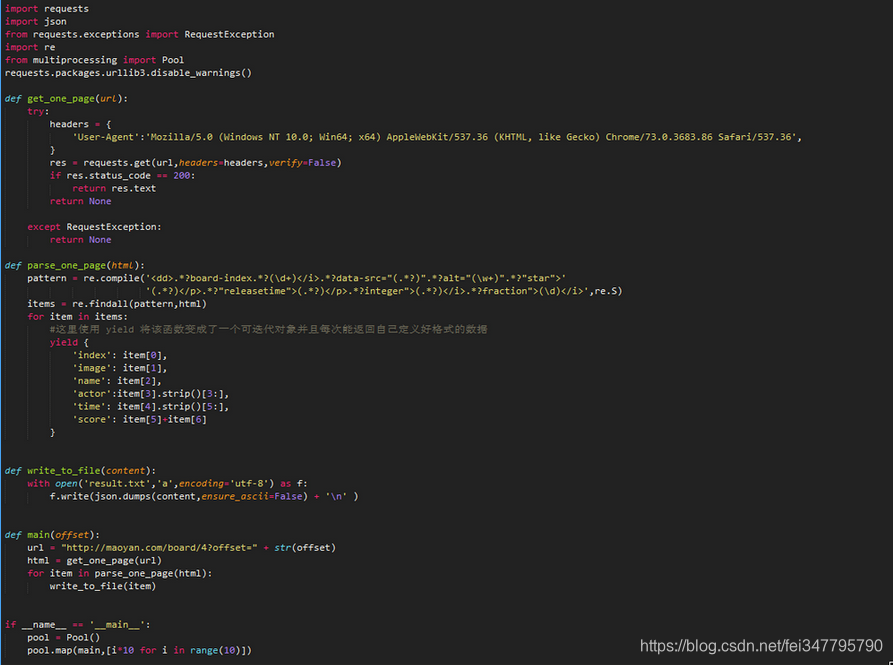
2.代码实现
spider.py
3.运行效果

转载地址:http://ganmf.baihongyu.com/
你可能感兴趣的文章
MSSQL复习笔记
查看>>
Spring基础知识汇总
查看>>
Chrome扩展插件
查看>>
log4j.xml 日志文件配置
查看>>
如何删除MySql服务
查看>>
BAT Java和Rti环境变量设置
查看>>
NodeJs npm install 国内镜像
查看>>
python3.5.2 mysql Exccel
查看>>
mysqlDump 导出多表,其中部分表有限制数据内容
查看>>
vi 替换方法
查看>>
BAT 相关
查看>>
ANT集成SVNANT访问SVN(Subversion)
查看>>
高可用架构-- MySQL主从复制的配置
查看>>
jvm调优-从eclipse开始
查看>>
构建微服务:Spring boot 入门篇
查看>>
jvm调优-命令大全(jps jstat jmap jhat jstack jinfo)
查看>>
Spring boot Myibatis
查看>>
spring boot(七):springboot+mybatis多数据源最简解决方案
查看>>
Spring Boot 笔记
查看>>
maven下手动导入ojdbc6.jar
查看>>